What's covered in the blog?
1. Documentation on the Oozie java API
2. Code of a sample java program that calls a oozie workflow with a java action to process some syslog generated log files. Instructions on loading sample data, workflow files and running the workflow are provided, along with some notes based on my learnings.
Version:
Oozie 3.3.0;
Related blogs:
Blog 1: Oozie workflow with hdfs and email actions
Blog 2: Oozie workflow with hdfs, email and hive actions
Blog 3: Oozie workflow with sqoop action (Hive-mysql; sqoop export)
Blog 4: Oozie workflow with java map-reduce (new API) action
Blog 5: Oozie workflow with streaming map-reduce action
Blog 6: Oozie workflow with java main action
Blog 7: Oozie workflow with Pig action
Blog 8: Oozie Java API for interfacing with oozie workflows
Blog 9: Oozie Web Service API for interfacing with oozie workflows
Blog 10: Oozie bundle & coordinator jobs
Your thoughts/updates:
If you want to share your thoughts/updates, email me at airawat.blog@gmail.com.
1.0. About the Oozie java API
Oozie provides a Java Client API that simplifies integrating Oozie with Java applications. This Java Client API is a convenience API to interact with Oozie Web-Services API.
The following code snippet shows how to submit an Oozie job using the Java Client API.
import org.apache.oozie.client.OozieClient;
import org.apache.oozie.client.WorkflowJob;
.
import java.util.Properties;
.
...
.
// get a OozieClient for local Oozie
OozieClient wc = new OozieClient("http://bar:11000/oozie");
.
// create a workflow job configuration and set the workflow application path
Properties conf = wc.createConfiguration();
conf.setProperty(OozieClient.APP_PATH, "hdfs://foo:8020/usr/tucu/my-wf-app");
.
// setting workflow parameters
conf.setProperty("jobTracker", "foo:8021");
conf.setProperty("inputDir", "/usr/tucu/inputdir");
conf.setProperty("outputDir", "/usr/tucu/outputdir");
...
.
// submit and start the workflow job
String jobId = wc.run(conf);
System.out.println("Workflow job submitted");
.
// wait until the workflow job finishes printing the status every 10 seconds
while (wc.getJobInfo(jobId).getStatus() == Workflow.Status.RUNNING) {
System.out.println("Workflow job running ...");
Thread.sleep(10 * 1000);
}
.
// print the final status o the workflow job
System.out.println("Workflow job completed ...");
System.out.println(wf.getJobInfo(jobId));
...
Source of the documentation, above:
http://archive.cloudera.com/cdh/3/oozie/DG_Examples.html#Java_API_Example2.0. Exercise
The java program below calls the workflow built in my blog 6 - include java code, workflow related files and sample data.
2.0.1. Sample data and sample workflow
2.0.2. Sample Java program to call workflow
Note: Ensure you replace configuration highlighted in yellow ochre with your cluster specific configuration.
import java.util.Properties;
import org.apache.oozie.client.OozieClient;
import org.apache.oozie.client.WorkflowJob;
public class myOozieWorkflowJavaAPICall {
public static void main(String[] args) {
OozieClient wc = new OozieClient("http://cdh-dev01:11000/oozie");
Properties conf = wc.createConfiguration();
conf.setProperty(OozieClient.APP_PATH, "hdfs://cdh-nn01.hadoop.com:8020/user/airawat/oozieProject/javaApplication/workflow.xml");
conf.setProperty("jobTracker", "cdh-jt01:8021");
conf.setProperty("nameNode", "hdfs://cdh-nn01.hadoop.com:8020");
conf.setProperty("queueName", "default");
conf.setProperty("airawatOozieRoot", "hdfs://cdh-nn01.hadoop.com:8020/user/airawat/oozieProject/javaApplication");
conf.setProperty("oozie.libpath", "hdfs://cdh-nn01.hadoop.com:8020/user/oozie/share/lib");
conf.setProperty("oozie.use.system.libpath", "true");
conf.setProperty("oozie.wf.rerun.failnodes", "true");
try {
String jobId = wc.run(conf);
System.out.println("Workflow job, " + jobId + " submitted");
while (wc.getJobInfo(jobId).getStatus() == WorkflowJob.Status.RUNNING) {
System.out.println("Workflow job running ...");
Thread.sleep(10 * 1000);
}
System.out.println("Workflow job completed ...");
System.out.println(wc.getJobInfo(jobId));
} catch (Exception r) {
System.out.println("Errors " + r.getLocalizedMessage());
}
}
}
2.0.3. Program output
Workflow job, 0000081-130613112811513-oozie-oozi-W submitted
Workflow job running ...
Workflow job running ...
Workflow job running ...
Workflow job running ...
Workflow job running ...
Workflow job running ...
Workflow job running ...
Workflow job completed ...
Workflow id[0000081-130613112811513-oozie-oozi-W] status[SUCCEEDED]
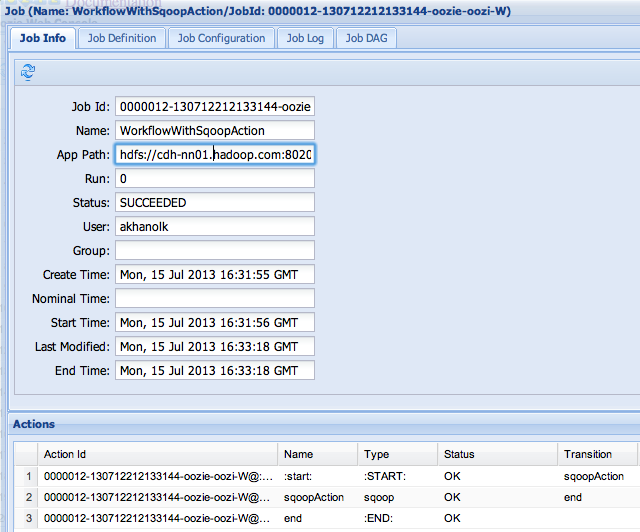
2.0.4. Oozie web console
http://YourOozieServer:TypicallyPort11000/oozie