1. Documentation on the Oozie sqoop action
2. A sample workflow (against syslog generated logs) that includes oozie sqoop action (export from hive to mysql). Instructions on loading sample data and running the workflow are provided, along with some notes based on my learnings.
For scheduling an Oozie worklflow containing a Sqoop action to be event driven - time or data availability driven, read my blog on Oozie coordinator jobs.
Versions covered:
Oozie 3.3.0; Sqoop (1.4.2) with Mysql (5.1.69 )
My blogs on Sqoop:
Blog 1: Import from mysql into HDFS
Blog 2: Import from mysql into Hive
Blog 3: Export from HDFS and Hive into mysql
Blog 4: Sqoop best practices
Blog 5: Scheduling of Sqoop tasks using Oozie
Blog 6: Sqoop2
My blogs on Oozie:
Blog 1: Oozie workflow - hdfs and email actions
Blog 2: Oozie workflow - hdfs, email and hive actions
Blog 3: Oozie workflow - sqoop action (Hive-mysql; sqoop export)
Blog 4: Oozie workflow - java map-reduce (new API) action
Blog 5: Oozie workflow - streaming map-reduce (python) action
Blog 6: Oozie workflow - java main action
Blog 7: Oozie workflow - Pig action
Blog 8: Oozie sub-workflow
Blog 9a: Oozie coordinator job - time-triggered sub-workflow, fork-join control and decision control
Blog 9b: Oozie coordinator jobs - file triggered
Blog 9c: Oozie coordinator jobs - dataset availability triggered
Blog 10: Oozie bundle jobs
Blog 11a: Oozie Java API for interfacing with oozie workflows
Blog 11b: Oozie Web Service API for interfacing with oozie workflows
Your thoughts/updates:
If you want to share your thoughts/updates, email me at airawat.blog@gmail.com.
About the oozie sqoop action
Apache Oozie documentation on Sqoop action:
http://archive.cloudera.com/cdh/3/oozie/DG_SqoopActionExtension.html
Salient features of the sqoop action:
Excerpt from Apache documentation..
- The sqoop action runs a Sqoop job synchronously.- The information to be included in the oozie sqoop action are the job-tracker, the name-node and Sqoop command or arg elements as well as configuration.- A prepare node can be included to do any prep work including hdfs actions. This will be executed prior to execution of the sqoop job.- Sqoop configuration can be specified with a file, using the job-xml element, and inline, using the configuration elements.- Oozie EL expressions can be used in the inline configuration. Property values specified in the configuration element override values specified in the job-xml file.
Note that Hadoop mapred.job.tracker and fs.default.name properties must not be present in the inline configuration.
As with Hadoop map-reduce jobs, it is possible to add files and archives in order to make them available to the Sqoop job.
Sqoop command:
The Sqoop command can be specified either using the command element or multiple arg elements.
- When using the command element, Oozie will split the command on every space into multiple arguments.- When using the arg elements, Oozie will pass each argument value as an argument to Sqoop. The arg variant should be used when there are spaces within a single argument. - All the above elements can be parameterized (templatized) using EL expressions.
Components of a workflow with sqoop action:

Sample application
Highlights:
For this exercise, I have loaded some syslog generated logs to hdfs and created a hive table.
I have also created a table in mysql that will be the destination of a report (hive query) we will run
Pictorial representation of the workflow:

Sample program:
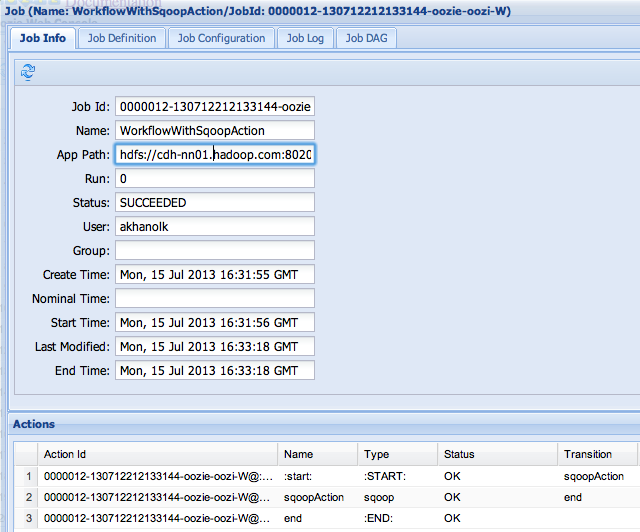
Oozie web console:
Screenshots..
Thanks a lot Anagha,your oozie post helps me alot in my deployment process...thank you very much..good day ..bye
ReplyDeletevery good post easy to uderstand, blog 2 is unable to open can share the latest link
ReplyDeleteIt was late to enter in Bigdata , but found relevant , will be glad for further post
ReplyDeleteThank you for this post...helped me to learn oozie
ReplyDeletePrivileged to read this informative blog on Hadoop.Commendable efforts to put on research the hadoop. Please enlighten us with regular updates on hadoop. Friends if you're keen to learn more about AI you can watch this amazing tutorial on the same.
ReplyDeletehttps://www.youtube.com/watch?v=1jMR4cHBwZE
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeleteRegards,
Big Data Hadoop Training in electronic city, Bangalore
thakyou it vry nice blog for beginners
ReplyDeletehttps://www.emexotechnologies.com/courses/big-data-analytics-training/big-data-hadoop-training/
It was really a nice article and i was really impressed by reading this Big data hadoop online Course
ReplyDeleteGood Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeletehttps://www.emexotechnologies.com/online-courses/big-data-hadoop-training-in-electronic-city/
Really very nice article,keep sharing more information with us .
ReplyDeletethank you....
Big data online training
Big data hadoop training
I think you did an awesome allahabad university bsc 3rd year Result job explaining it. Sure beats having to research vikram university pg result it on my own. Thanks
ReplyDeleteNice read, I just passed this onto a friend who was doing a little research on that. Sooryavanshi Full Movie 2021
ReplyDelete