1.0. What's covered in the blog?
1. Oozie documentation on coordinator job, sub workflow, fork-join, and decision controls2. A sample application that includes components of a oozie time triggered coordinator job - scripts/code, sample data and commands; Oozie actions covered: hdfs action, email action, java main action, hive action; Oozie controls covered: decision, fork-join; The workflow includes a sub-workflow that runs two hive actions concurrently. The hive table is partitioned; Parsing - hive-regex, and Java-regex. Also, the java mapper, gets the input directory path and includes part of it in the key.
Version:
Oozie 3.3.0;
Related blogs:
Blog 1: Oozie workflow - hdfs and email actions
Blog 2: Oozie workflow - hdfs, email and hive actions
Blog 3: Oozie workflow - sqoop action (Hive-mysql; sqoop export)
Blog 4: Oozie workflow - java map-reduce (new API) action
Blog 5: Oozie workflow - streaming map-reduce (python) action
Blog 6: Oozie workflow - java main action
Blog 7: Oozie workflow - Pig action
Blog 8: Oozie sub-workflow
Blog 9a: Oozie coordinator job - time-triggered sub-workflow, fork-join control and decision control
Blog 9b: Oozie coordinator jobs - file triggered
Blog 9c: Oozie coordinator jobs - dataset availability triggered
Blog 10: Oozie bundle jobs
Blog 11: Oozie Java API for interfacing with oozie workflows
Blog 12: Oozie workflow - shell action +passing output from one action to another
Blog 13: Oozie workflow - SSH action
Your thoughts/updates:
If you want to share your thoughts/updates, email me at airawat.blog@gmail.com.
Related blogs:
Blog 1: Oozie workflow - hdfs and email actions
Blog 2: Oozie workflow - hdfs, email and hive actions
Blog 3: Oozie workflow - sqoop action (Hive-mysql; sqoop export)
Blog 4: Oozie workflow - java map-reduce (new API) action
Blog 5: Oozie workflow - streaming map-reduce (python) action
Blog 6: Oozie workflow - java main action
Blog 7: Oozie workflow - Pig action
Blog 8: Oozie sub-workflow
Blog 9a: Oozie coordinator job - time-triggered sub-workflow, fork-join control and decision control
Blog 9b: Oozie coordinator jobs - file triggered
Blog 9c: Oozie coordinator jobs - dataset availability triggered
Blog 10: Oozie bundle jobs
Blog 11: Oozie Java API for interfacing with oozie workflows
Blog 12: Oozie workflow - shell action +passing output from one action to another
Blog 13: Oozie workflow - SSH action
Your thoughts/updates:
If you want to share your thoughts/updates, email me at airawat.blog@gmail.com.
2.0. Oozie sub-workflow
The sub-workflow action runs a child workflow job, the child workflow job can be in the same Oozie system or in another Oozie system. The parent workflow job will wait until the child workflow job has completed.
Syntax:

The child workflow job runs in the same Oozie system instance where the parent workflow job is running.
The app-path element specifies the path to the workflow application of the child workflow job.
The propagate-configuration flag, if present, indicates that the workflow job configuration should be propagated to the child workflow.
The configuration section can be used to specify the job properties that are required to run the child workflow job. The configuration of the sub-workflow action can be parameterized (templatized) using EL expressions.
Link to Apache documentation:
http://oozie.apache.org/docs/3.3.0/WorkflowFunctionalSpec.html#a3.2.6_Sub-workflow_Action
Note:
For a typical on-demand workflow, you have core components - job.properties and workflow.xml. For a sub workflow, you need yet another workflow.xml that clearly defines activities to occur in the sub-workflow. In the parent workflow, the sub-workflow is referenced. To keep it neat, best to have a sub-directory to hold the sub-workflow core components. Also, a single job.properties is sufficient.
E.g.
workflowAppPath
workflow.xml
job.properties
Any other lib/archives/files etc
subWorkflowAppPath
workflow.xml
3.0. Coordinator job
Users typically run map-reduce, hadoop-streaming, hdfs and/or Pig jobs on the grid. Multiple of these jobs can be combined to form a workflow job. Oozie, Hadoop Workflow Systemdefines a workflow system that runs such jobs.
Commonly, workflow jobs are run based on regular time intervals and/or data availability. And, in some cases, they can be triggered by an external event. Expressing the condition(s) that trigger a workflow job can be modeled as a predicate that has to be satisfied.
The workflow job is started after the predicate is satisfied. A predicate can reference to data, time and/or external events. In the future, the model can be extended to support additional event types.
It is also necessary to connect workflow jobs that run regularly, but at different time intervals. The outputs of multiple subsequent runs of a workflow become the input to the next workflow. For example, the outputs of last 4 runs of a workflow that runs every 15 minutes become the input of another workflow that runs every 60 minutes. Chaining together these workflows result it is referred as a data application pipeline.
The Oozie Coordinator system allows the user to define and execute recurrent and interdependent workflow jobs (data application pipelines). Real world data application pipelines have to account for reprocessing, late processing, catchup, partial processing, monitoring, notification and SLAs.
Link to Apache documentation:
http://oozie.apache.org/docs/3.3.0/CoordinatorFunctionalSpec.html
4.0. Decision control
A decision node enables a workflow to make a selection on the execution path to follow. The behavior of a decision node can be seen as a switch-case statement.
A decision node consists of a list of predicates-transition pairs plus a default transition. Predicates are evaluated in order or appearance until one of them evaluates to true and the corresponding transition is taken. If none of the predicates evaluates to true the default transition is taken.
Predicates are JSP Expression Language (EL) expressions (refer to section 4.2 of this document) that resolve into a boolean value, true or false. For example:
${fs:fileSize('/usr/foo/myinputdir') gt 10 * GB}
Syntax:

The name attribute in the decision node is the name of the decision node.
Each case elements contains a predicate an a transition name. The predicate ELs are evaluated in order until one returns true and the corresponding transition is taken.
The default element indicates the transition to take if none of the predicates evaluates to true .
All decision nodes must have a default element to avoid bringing the workflow into an error state if none of the predicates evaluates to true.
Link to Apache documentation:
http://oozie.apache.org/docs/3.3.0/WorkflowFunctionalSpec.html#a3.1.4_Decision_Control_Node
5.0. Fork-Join controls
A fork node splits one path of execution into multiple concurrent paths of execution.
A join node waits until every concurrent execution path of a previous fork node arrives to it.
The fork and join nodes must be used in pairs.
The join node assumes concurrent execution paths are children of the same fork node.
Syntax:

The name attribute in the fork node is the name of the workflow fork node. The start attribute in the path elements in the fork node indicate the name of the workflow node that will be part of the concurrent execution paths.
The name attribute in the join node is the name of the workflow join node. The to attribute in the join node indicates the name of the workflow node that will executed after all concurrent execution paths of the corresponding fork arrive to the join node.
Link to Apache documentation:
http://oozie.apache.org/docs/3.3.0/WorkflowFunctionalSpec.html#a3.1.5_Fork_and_Join_Control_Nodes
6.0. Helpful sites
https://cwiki.apache.org/confluence/display/OOZIE/Map+Reduce+Cookbook
https://github.com/yahoo/oozie/wiki/Oozie-WF-use-cases
7.0. Sample coordinator application
Highlights:
The sample application includes components of a oozie (time initiated) coordinator application - scripts/code, sample data and commands; Oozie actions covered: hdfs action, email action, java main action, hive action; Oozie controls covered: decision, fork-join; The workflow includes a sub-workflow that runs two hive actions concurrently. The hive table is partitioned; Parsing uses hive-regex, and Java-regex. Also, the java mapper, gets the input directory path and includes part of it in the key.
Pictorial overview of application:


Components of application:

Application details:
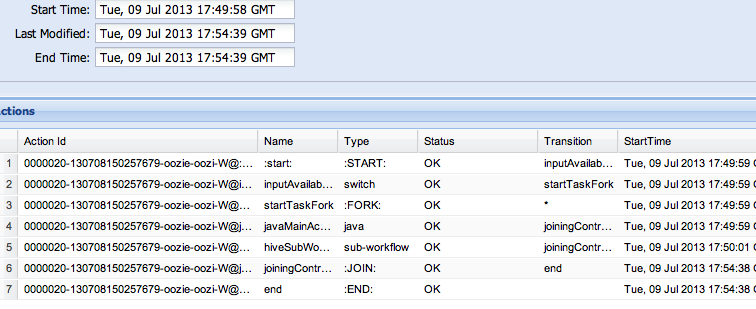
Oozie web console:
Highlights:
The sample application includes components of a oozie (time initiated) coordinator application - scripts/code, sample data and commands; Oozie actions covered: hdfs action, email action, java main action, hive action; Oozie controls covered: decision, fork-join; The workflow includes a sub-workflow that runs two hive actions concurrently. The hive table is partitioned; Parsing uses hive-regex, and Java-regex. Also, the java mapper, gets the input directory path and includes part of it in the key.
Pictorial overview of application:
Components of application:
Oozie web console:
Screenshots from execution of sample program


Important information thank you providing this important information on Big data Hadoop online training Bangalore
ReplyDeletethakyou it vry nice blog for beginners
ReplyDeletehttps://www.emexotechnologies.com/courses/big-data-analytics-training/big-data-hadoop-training/
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeletehttps://www.emexotechnologies.com/online-courses/big-data-hadoop-training-in-electronic-city/
Thank you.Well it was nice post and very helpful information on Big Data Hadoop Online Training Hyderabad
ReplyDeleteКонтакторы позволяют управлять освещением и оборудованием автоматически.
ReplyDelete