1.0. What's covered in the blog?
1) Apache documentation on bundle jobs
2) A sample bundle application with two coordinator apps - one that it time triggered, another that is dataset availability triggered. Oozie actions covered: hdfs action, email action, java main action, sqoop action (mysql database); Includes oozie job property files, workflow xml files, sample data (syslog generated files), java program (jar) for log parsing, commands;
Version:
Oozie 3.3.0;Related blogs:
Blog 1: Oozie workflow - hdfs and email actions
Blog 2: Oozie workflow - hdfs, email and hive actions
Blog 3: Oozie workflow - sqoop action (Hive-mysql; sqoop export)
Blog 4: Oozie workflow - java map-reduce (new API) action
Blog 5: Oozie workflow - streaming map-reduce (python) action
Blog 6: Oozie workflow - java main action
Blog 7: Oozie workflow - Pig action
Blog 8: Oozie sub-workflow
Blog 9a: Oozie coordinator job - time-triggered, with sub-workflow, fork-join control and decision control
Blog 9b: Oozie coordinator jobs - file triggered
Blog 9c: Oozie coordinator jobs - dataset availability triggered
Blog 10: Oozie bundle jobs
Blog 11a: Oozie Java API for interfacing with oozie workflows
Blog 11b: Oozie Web Service API for interfacing with oozie workflows
2.0. About Oozie bundle jobs
The first coordinator job is time triggered. The start time is defined in the bundle job.properties file. It runs a workflow, that includes a java main action. The java program parses some log files and generates a report. The output of the java action is a dataset (the report) which is the trigger for the next coordinator job.
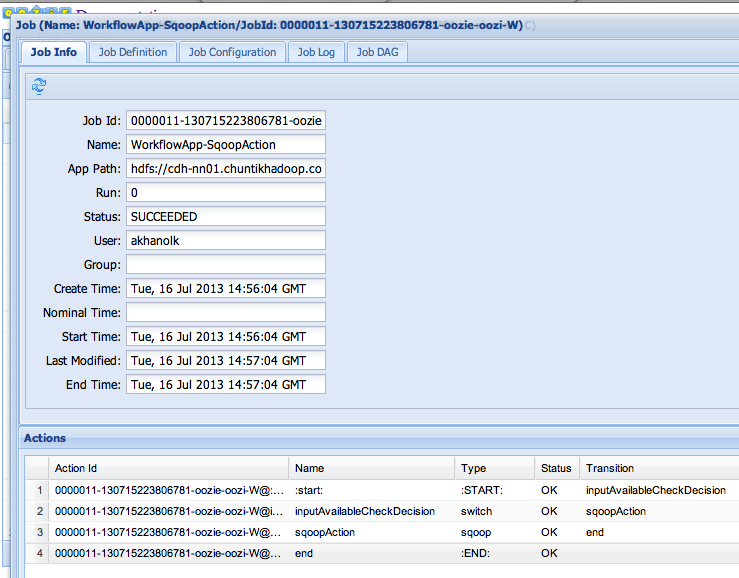
The second coordinator job gets triggered upon availability of the file _SUCCESS in the output directory of the workflow application of the first coordinator application. It executes a workflow that has a sqoop action; The sqoop action pipes the output of the first coordinator job to a mysql database.
 Components of the bundle application:
Components of the bundle application:

Bundle application details:




Excerpt from Apache documentation-
Bundle is a higher-level oozie abstraction that will batch a set of coordinator applications. The user will be able to start/stop/suspend/resume/rerun in the bundle level resulting a better and easy operational control.
More specififcally, the oozie Bundle system allows the user to define and execute a bunch of coordinator applications often called a data pipeline. There is no explicit dependency among the coordinator applications in a bundle. However, a user could use the data dependency of coordinator applications to create an implicit data application pipeline.
Apache documentation:
http://oozie.apache.org/docs/3.3.0/BundleFunctionalSpec.html#a1._Bundle_Overview
A bundle job can have one to many coordinator jobs.
A coordinator job can have one to many workflows.
A workflow can have one to many actions.
3.0. Sample program
Highlights:
The sample bundle application is time triggered. The start time is defined in the bundle job.properties file. The bundle application starts two coordinator applications- as defined in the bundle definition file - bundleConfirguration.xml.The first coordinator job is time triggered. The start time is defined in the bundle job.properties file. It runs a workflow, that includes a java main action. The java program parses some log files and generates a report. The output of the java action is a dataset (the report) which is the trigger for the next coordinator job.
The second coordinator job gets triggered upon availability of the file _SUCCESS in the output directory of the workflow application of the first coordinator application. It executes a workflow that has a sqoop action; The sqoop action pipes the output of the first coordinator job to a mysql database.
Pictorial overview of the job:
Oozie web console - screenshots:

thakyou it vry nice blog for beginners
ReplyDeletehttps://www.emexotechnologies.com/courses/big-data-analytics-training/big-data-hadoop-training/
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeletehttps://www.emexotechnologies.com/online-courses/big-data-hadoop-training-in-electronic-city/