What's covered in the blog?
1. Documentation on the Oozie hive action2. A sample workflow that includes fs action, email action, and hive action (query against some syslog generated log files).
Version:
Oozie 3.3.0
My other blogs on Oozie:
Blog 1: Oozie workflow - hdfs and email actions
Blog 2: Oozie workflow - hdfs, email and hive actions
Blog 3: Oozie workflow - sqoop action (Hive-mysql; sqoop export)
Blog 4: Oozie workflow - java map-reduce (new API) action
Blog 5: Oozie workflow - streaming map-reduce (python) action
Blog 6: Oozie workflow - java main action
Blog 7: Oozie workflow - Pig action
Blog 8: Oozie sub-workflow
Blog 9a: Oozie coordinator job - time-triggered sub-workflow, fork-join control and decision control
Blog 9b: Oozie coordinator jobs - file triggered
Blog 9c: Oozie coordinator jobs - dataset availability triggered
Blog 10: Oozie bundle jobs
Blog 11: Oozie Java API for interfacing with oozie workflows
Blog 12: Oozie workflow - shell action +passing output from one action to another
Blog 13: Oozie workflow - SSH action
Your thoughts/updates:
If you want to share your thoughts/updates, email me at airawat.blog@gmail.com.
About the Hive action
http://archive.cloudera.com/cdh4/cdh/4/oozie/DG_HiveActionExtension.htmlSalient features of the hive action:
- Runs the specified hive job synchronously (the workflow job will wait until the Hive job completes before continuing to the next action).
- Can be configured to create or delete HDFS directories before starting the Hive job.
- Supports Hive scripts with parameter variables, their syntax is ${VARIABLES} .
- Hive configuration needs to be specified as part of the job submission
- Oozie EL expressions can be used in the inline configuration. Property values specified in the configuration element override values specified in the job-xml file.
- Note that Hadoop mapred.job.tracker and fs.default.name properties must not be present in the inline configuration.
- As with Hadoop map-reduce jobs, it is possible to add files and archives in order to make them available to the Hive job.
Components of a workflow with hive action:
For a workflow with (just a) hive action, the following are required:
1. workflow.xml
2. job.properties
3. Any files, archives, jars you want to add
4. hive-site.xml
5. Hive query scripts
Refer sample program below.
Sample program
Highlights:
The workflow application runs a report on data in Hive. The input is log data (Syslog generated) in Hive, output is a table containing the report results in Hive.Pictorial overview of application:
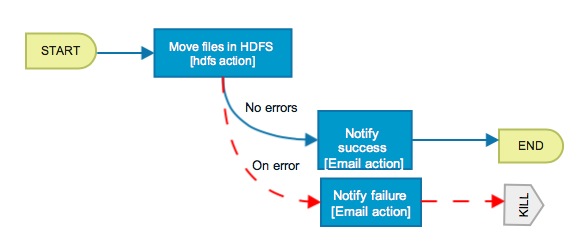
Application:
Oozie web console:
Screenshots of application execution:
Hi,
ReplyDeletecan you please show me how to move files from local directory to Hdfs every hour using oozie workflow.
i have tried oozie fs action but it only works if im moving file from one folder to another in hdfs.
i want to move a file from local directory to hdfs. please help!!!
Hi Khatutshelo-
DeleteCheck out my blog 13 on Oozie ssh action.
Cheers,
Anagha
Hi Anagha, What is the difference between ssh action and shell action? When should i go for shh action over the shell action. Could you please give some idea on the same.
Deletei have also same problem could plese post the process
ReplyDeleteThere are several avenues to ingesting data to HDFS.
ReplyDeleteHere is a good discussion on this topic to help arrive at the best solution based on your requirements-
http://www.linkedin.com/groups/Data-Ingestion-Into-Hadoop-3638279.S.199779955
Hive + oozie workflow problem.
ReplyDeletemy task is to create an oozie workflow to Load Data to Hive tables every hour.
i am using Hue 2.3.0
When i run the command: LOAD DATA INPATH '/user/username1/data/data3.txt' INTO TABLE raw_data; it works perfectly, data gets loaded to the hive table.
*When i run the same command on oozie workflow the job get killed at 66% and the error message is* Main class [org.apache.oozie.action.hadoop.HiveMain], exit code [10001]
----
but whe i replace "LOAD DATA INPATH '/user/username1/data/data3.txt' INTO TABLE raw_data;" with "create external table table_data (json string) LOCATION '/user/username_k/20130925_data';" the oozie workflow works properly
May you please help.
Khathutshelo, can you send me your scripts/code, directory structure, samples files etc so I can try to replicate? Thanks.
ReplyDeleteHi Anagha,
ReplyDeletei am using Hue 2.3.0
-----------------------------------
what i did is:
create an external table1 where the location is the HDFS directory with data, it has 4 columns
create another external table2 with 3 columns and a partition column
write a script to Insert table2 with partition from table1
the problem is insert script works properly if i put it on the query editor but throws an 'Table not found'error
table1 and table2 are both in the same database(adhoc)
hive-script.q
---------------------
INSERT OVERWRITE TABLE production1 PARTITION(dt, hour)
SELECT a, b, datastring, hour FROM staging2;
--------------------------------------------------------------------------------------------------------------------
since the partition name will be created automatically, i decide not to use the following method:
ReplyDeleteAlter table SysLogEvents Add IF NOT EXISTS partition(node="cdh-vms",year=2013, month=05)
however i make sure that the first table has 1 more column compared to the second table that has partition. the first column of the first table become the patirtion name on the second table.
eg table1 has 3 columns and table2 has 2 column and a partition column
Hi Anagha,
ReplyDeleteThanks for the blog. Would you mind giving an example of creating a workflow where in you can pass parameters. And also how to run it.
Thanks for the wonderful blog and helping us out !
Hi,
ReplyDeleteI'm planning to pass oozie workflow as a parameter and input value to hive script how to do this please advice.
create table wfl_tbl(date string,wf_id string);
insert into wfl_tbl select '${wf:id()}', '2014-015-15' from dummy ;
I'm submitting the above from Hue oozie editor it is taing ${wf:id()}. Please advice.
Regards,
R
Hi Anagha,
ReplyDeleteI am trying to create a directory based on the job_id created after running the oozie job using a shell script. can you help me ? can we pass JOB_ID as parameter while executing the script. id so how to do it..?
interesting blog to read.. After reading this blog i learnt more useful information from this blog.. thanks a lot for sharing this blog
ReplyDeletebest big data training | hadoop training institute in chennai | big data training institute in chennai
thakyou it vry nice blog for beginners
ReplyDeletehttps://www.emexotechnologies.com/courses/big-data-analytics-training/big-data-hadoop-training/
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeletehttps://www.emexotechnologies.com/online-courses/big-data-hadoop-training-in-electronic-city/
I feel really happy to have seen your webpage and look forward to so many more entertaining times reading here. Thanks once more for all the details.
ReplyDeleteDevops Course Training in Chennai |Best Devops Training Institute in Chennai
Selenium Course Training in Chennai |Best Selenium Training Institute in Chennai
Java Course Training in Chennai | Best Java Training Institute in Chennai
Hey, would you mind if I share your blog with my twitter group? There’s a lot of folks that I think would enjoy your content. Please let me know. Thank you.
ReplyDeleteJava Training in Chennai | J2EE Training in Chennai | Advanced Java Training in Chennai | Core Java Training in Chennai | Java Training institute in Chennai
Nice post. it was so informative and keep sharing. Home lifts India
ReplyDelete